
 За последние два года я представил вам достаточно большое количество утилит для системного администрирования. Мы узнали, как правильно анализировать круг проблем путем тщательного исследования симптомов и выявления причин. Мы изучили strace и lsof, которые являются достаточно мощными инструментами. Мы сфокусировались на профилировании и аудите системы. Мы поклонялись всемогущему отладчику GNU Debugger (gdb). Теперь пришло время объединить мощь всех этих программ в одном мега-руководстве.
За последние два года я представил вам достаточно большое количество утилит для системного администрирования. Мы узнали, как правильно анализировать круг проблем путем тщательного исследования симптомов и выявления причин. Мы изучили strace и lsof, которые являются достаточно мощными инструментами. Мы сфокусировались на профилировании и аудите системы. Мы поклонялись всемогущему отладчику GNU Debugger (gdb). Теперь пришло время объединить мощь всех этих программ в одном мега-руководстве.
Сегодня мы будем использовать все эти утилиты плюс некоторое количество приемов и советов, изложенных в моих руководствах по хакингу, чтобы попробовать попытаться решить казалось бы неразрешимые проблемы. Мы рассмотрим вопрос с нескольких точек зрения, каждый раз используя разные инструменты и показывая новые грани проблемы, пока не разрешим ее. Это будет нелегко, однако это, вероятно, будет уникальным многоцелевым руководством по системному администрированию и отладке среди тех, которые вы прочитали за очень долгое время.
Имеющаяся проблема
Итак, предположим, что у нас медленно происходит загрузка приложений. Вам приходится ждать 5 - 10 секунд, пока появится окно программы. Иногда все работает быстро, но вы не можете понять, почему. Обычно проблема возникает после выхода из сеанса или перезагрузки. Самое неприятное то, что если вы запускаете те же программы с помощью sudo или как or root, никаких задержек не наблюдается и все, кажется, работает нормально. Как же диагностировать такую проблему?
Правила!
Если вы хотите стать компетентным системным наладчиком, есть несколько желательных к исполнению правил, которым вы должны следовать, когда пытаетесь решить трудную задачу. Хорошо, если вопрос тривиальный и решается за пару минут. Однако если вы и ваши коллеги не можете разрешить проблему в течение часа, необходимо подумать и решать ее методически.
Будьте методичным
Имея стереотипный подход, вы можете выглядеть как нуб - или как очень компетентный человек. Вам выбирать. Вы можете обладать универсальной стратегией, применимой к решению любой проблемы, будь то ремонт самолета или взлом ядра операционной системы.
Всегда начинаем с простого
Теоретически, вы можете попробовать решить любую проблему сразу с помощью gdb, но вряд ли это будет рациональным использованием вашего интеллекта и времени. Вы должны всегда начинать с простых вещей. Проверьте системные логи на наличие странных ошибок. Запустите top, чтобы проверить загрузку процессора и потребление памяти.
Сравнение с исправно работающей системой
Это не всегда возможно, но если у вас есть машина с идентичным железом и таким же набором программного обеспечения, на которой не проявляется данная проблема, либо одинаковые сценарии нагрузки дают разные результаты, вы можете попробовать сравнить их между собой, чтобы найти причину неполадок. Это будет нелегко сделать, однако поиск - это наиболее мощный инструмент в такого рода ситуациях, и он применим как к механическим, так и к программным проблемам.
Теперь мы готовы копнуть глубже.
Симптомы
Нормально работающая система загружает xclock (простая графическая утилита, которую мы использовали в качестве теста) менее чем за секунду. При наличии проблем ее загрузка может занять до 10 секунд. Теперь мы знаем, что проблема имеется, но не знаем, в чем она заключается.
Strace
На данном этапе хорошей идеей будет использование strace. Прежде чем отслеживать каждый системный вызов в бесконечных логах, мы может оценить ситуацию в целом, запустив программу с флагом -c и посмотреть ее вывод.
Лог strace в нормально работающей системе
Вот что мы видим в данном случае: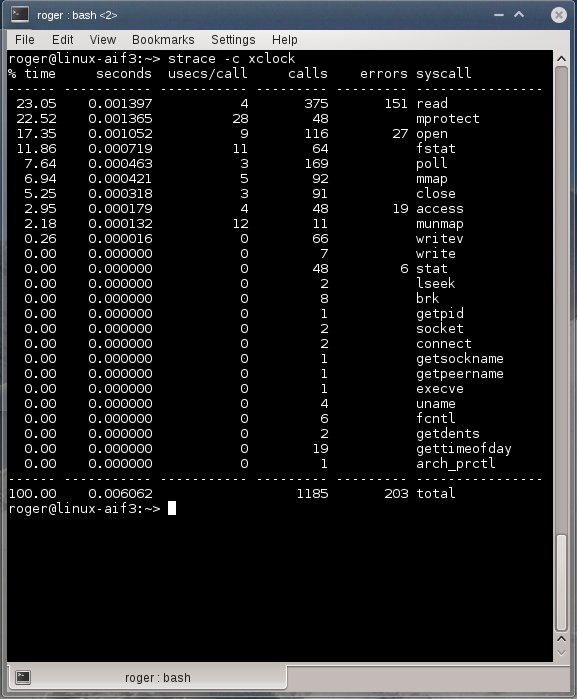
Лог strace в проблемной системе
То же самое при наличии ошибок: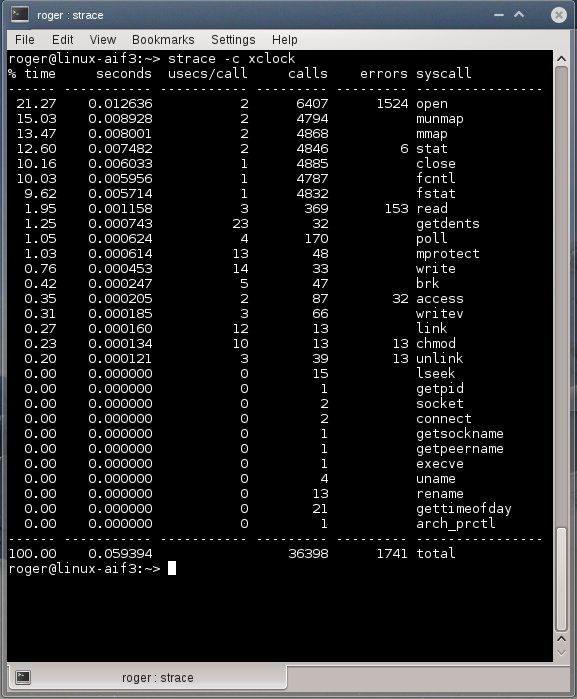
Сопоставление данных strace
Я привел рядом два результата strace. Видно, что поведение системы в двух вышеописанных случаях кардинально отличается.
В нормально работающей системе четыре верхних системных вызова - это read, mprotect, open и fstat. Всего у нас от нескольких десятков до нескольких сотен вызовов, среди которых имеется некоторое количество ошибок, связанных, вероятно, с поиском файлов в $PATH. Еще один важный элемент - время выполнения, которое составляет 1-2 милисекунды на каждый из четырех вызовов.
В проблемной системе лидируют open, munmap, mmap и stat. Более того, количество вызовов теперь измеряется тысячами, а время выполнения в 10-20 раз больше, чем было в нормальной системе.
Ltrace
Теперь мы воспользуемся ltrace и возможно узнаем что-то еще. Налицо значительная разница в поведении системных выводов, но мы не знаем, что является причиной проблемы. Возможно мы сможем это выяснить, изучив поведение библиотек, для чего и предназначена ltrace. Мы снова будем использовать флаг -c, чтобы увидеть конечный результат.
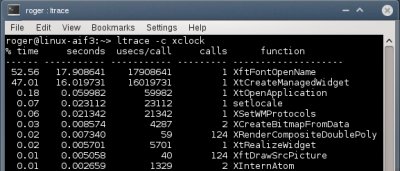
Лог ltrace в нормально работающей системе
Здесь целый пласт новой информации. Самая затратная функция библиотеки - создание виджета xclock, которая занимает 20 милисекунд, что составляет почти 40% от всего времени выполнения. На втором месте XftFontOpenName.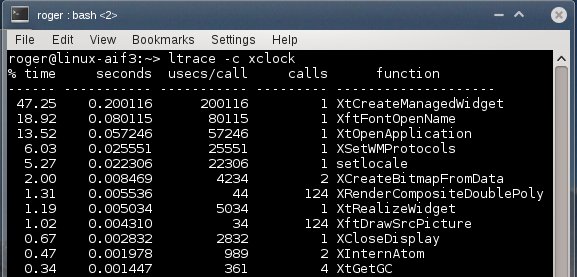
Лог ltrace в проблемной системе
Здесь мы видим кое-что другое. Лидирует функция The XftFontOpenName, которая выполняется в течение 18 секунд. На втором месте создание виджета с не менее впечатляющими 16 секундами. Больше ничего заслуживающего внимания не обнаруживается.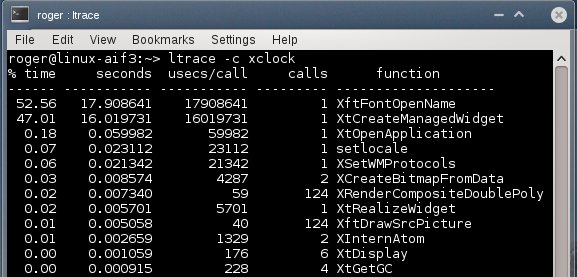
Сопоставление данных ltrace
Мы можем определенно сказать, что с шрифтами что-то не так. В нормальной системе вызов соответствующей библиотеки происходит практически мгновенно, в то время как в проблемной он длится почти 20 секунд. Сопоставляя логи, мы можем теперь прояснить картину. Большая длительность вызова функции, отвечающей за создание виджета, объясняет столь медленное появление окна программы. Более того, это прекрасно совмещается с огромным количеством системных вызовов и ошибок. Теперь у нас есть ключ к решению проблемы.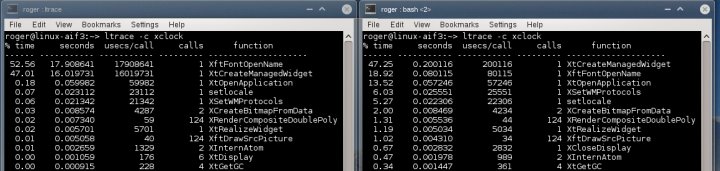
Дополнительный анализ с помощью vmstat
Некоторые могут сказать, что у нас уже достаточно информации - проблема в шрифтах. Но если вы не уверены на все 100%, можно попробовать узнать еще больше с помощью vmstat.
Нормально работающая система
vmstat выдает полезную информацию об использовании памяти и CPU. Мы уже говорили об этой утилите ранее, поэтому я не буду повторяться. Сегодня нас интересуют поля метрик CPU в последних пяти столбцах вывода программы, особенно два из них, помеченные как us и sy, а также поля cs и in в разделе system.
Поля us и sy показывают степень использования процессора пользователем и системой соответственно. Поля cs и in относятся к переключениям контекста и прерываниям. Первая метрика показывает примерно, как часто запущенный процесс отказывается от своего места в очереди запросов в пользу другого ожидающего процесса. Другими словами, это переключение контекста между процессами. Прерывания показывают, сколько раз работающие процессы получали доступ к оборудованию, например доступ к диску для чтения данных из файловой системы, опрос экрана или клавиатуры и т.д.
Давайте посмотрим, что происходит, когда мы запускаем программу xclock. Игнорируем первую строку, так как в ней показаны средние значения с момента последнего запуска системы. Мы можем видеть краткий всплеск нагрузки на процессор, который хорошо соотносится с большим количеством прерываний и переключений контекста. Время запуска xclock показано в четвертой строке.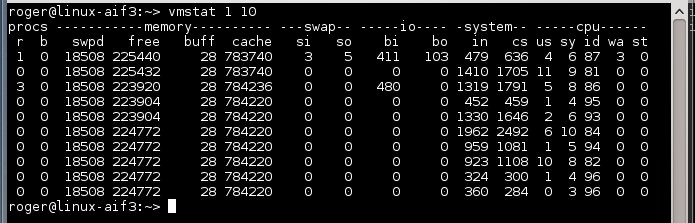
Проблемная система
Здесь ситуация несколько отличается. Мы можем видеть значительное увеличение нагрузки на процессор в течение почти 5 - 7 секунд. Однако у нас намного меньше переключений контекста и намного больше прерываний. О чем это говорит? Мы видим, что xclock, который является интерактивным приложением и поэтому должен обрабатываться как интерактивный процесс, при запуске ведет себя как вычислительный (пакетный) процесс.
От интерактивных процессов мы ждем как можно большей отзывчивости, что подразумевает множество переключений контекста и низкую активность процессора, так что мы получаем от планировщика динамический приоритет и тратим как можно меньше времени на вычисления, отдавая контроль пользователю. Однако в нашем случае процесс имеет намного меньше переключений контекста и намного сильнее нагружает процессор, что типично для пакетных процессов. Это означает, что производится намного больше вычислений: наша система читает шрифты и создает кэш, в то время как мы ждем запуска xclock. Это также объясняет повышение активности системы ввода/вывода, так как данные операции выполняются в нашей локальной файловой системе.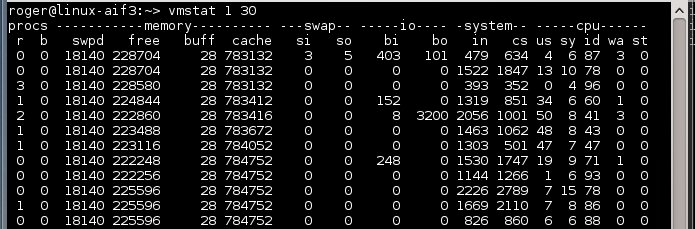
Сейчас важно подчеркнуть, что вышеприведенный анализ будет совершенно бесполезен, если вы не знаете, как работает ваш процесс и что он должен делать. Однако, если у вас есть хотя бы намек на идею, даже скучный список чисел в выводе vmstat может дать вам огромное количество информации.
Решение проблемы
Я полагаю, мы получили достаточно информации, чтобы решить ее. Что-то не то со шрифтами. Факт столь долгого запуска приложения говорит о том, что кэш шрифтов создается каждый раз заново, что, в свою очередь, свидетельствует о том, что запущенная пользователем программа не имеет доступа к системному кэшу шрифтов. Это также объясняет, почему при запуске программы с правами root подобной проблемы не наблюдается.
Приложение работает медленно. Логи strace показывают открытые ошибки. Теперь мы можем запустить полную сессию strace и найти точные пути этих ошибок. Мы будем использовать флаг -e для открытых системных вызовов, чтобы сократить вывод, и мы будем увеличивать длину строки используя флаг -s, чтобы получить всю информацию о потерянных путях. Мы хотим узнать о шрифтах, недоступных для чтения пользователем.
Но нам не нужно этого делать, так как эту информацию мы уже получили с помощью ltrace, которая показала, что проблема кроется в чтении шрифтов. Этот библиотечный вызов блокирует создание виджета, поэтому приложение запускается медленно. vmstat обеспечил нас дополнительной информацией, которая помогла сузить круг поиска.
Если мы проверим системный кэш шрифтов, расположенный в /var/cache/fontconfig, мы увидим, что эти шрифты созданы с правами доступа 600, то есть они доступны для чтения только root. Если мы сменим права на 644, мы решим проблему и все наши программы будут запускаться быстро. Кроме того, тем самым мы сэкономим дисковое пространство, так как не будет необходимости создания своей копии шрифтов для каждого пользователя в своей домашней директории.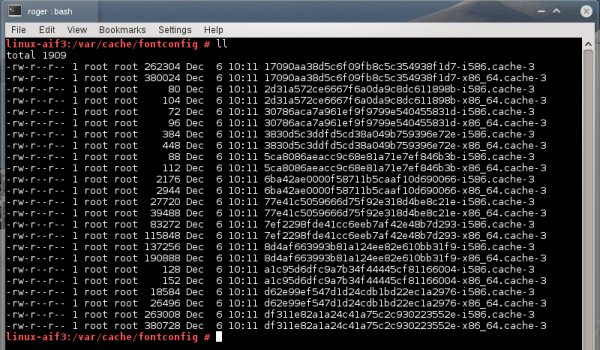
Использование lsof для отладки системы
Теперь я хотел бы кратко описать другую проблему. Она полностью отличается от предыдущего примера. Более того, в данном случае strace и ltrace полностью бесполезны, так как процесс завис. Мы на самом деле не понимаем, что происходит, но все утилиты, описанные выше, помочь нам не могут. Встречайте lsof.
Итак, у нас есть процесс Java, который завис и не отвечает. Java всегда выглядела непривлекательно и поставлялась с отвратительным механизмом обработки исключений, но мы должны отследить ошибку, а все обычные инструменты не могут дать нам никакой полезной информации. Вот, что мы видим в выводе strace:
futex(0x562d0be8, FUTEX_WAIT, 18119, NULL
Но если вы проверите этот процесс с помощью lsof, то увидите что-то вроде этого:
java 11511 user 32u ipv4 1920022313 TCP
rogerbox:44332->rogerbox:22122 (SYN_SENT)
Надеюсь, вы увидите не смайлы 
Мы можем видеть, что Java использует два порта IPv4 для внутренней коммуникации. Она отправляет пакет с одного порта в другой, инициализируя TCP-соединение. По каким-то причинам сервер, прослушивающий порт 22122, не отвечает.
На этом этапе вы можете проверить, почему пакет не принимается сервером. Нет ли проблем с маршрутизацией? К локальной машине это, вероятно, не относится, но, возможно, место назначения пакета находится в другом месте? Нет ли проблем с файерволом? Можете ли вы подключиться к соответствующей машине и порту с использованием telnet? На этой стадии у вас еще нет всех инструментов для исправления ошибки, но вы уже знаете, что является причиной проблем с Java. Поэтому для всех практических целей можно считать, что проблема решена.
Заключение
Я уверен, что вам понравилось это руководство. Я постарался объединить в этой статье все - рациональное мышление, методический подход к решению проблемы, разнообразное использование отладочных утилит для выявления причин проблемы, включая сравнение системных вызовов и библиотечных функций между нормально работающей и проблемной системами, использование vmstat для понимания поведения процессов, и так далее. В качестве бонуса мы изучили использование lsof для ошибок, связанных с сетевыми функциями.
Теперь вы сможете изменить подход к администрированию системы. Возможно, решение сложных проблем упростится, если вы будете придерживаться дисциплины последовательного продвижения к решению с использованием описанных методов и утилит. Если вы встретите затруднения, то всегда можете обратиться к моим руководствам, в которых описано более тридцати утилит и скриптов, которые могут помочь вам в путешествии в самое сердце системы. На этом все.
Взято отсюда.

